
在迈向更智能化的机器人应用领域,感知技术是至关重要的前提和基础。近期,华东理工大学信息科学与工程学院在计算机视觉国际顶级会议International Conference on Computer Vision 2023(ICCV2023,中国计算机学会推荐国际学术会议A类,CCF-A类)上,分别以“CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation(CMDA:跨模态域自适应夜晚语义分割)”和“GasMono: Geometry-Aided Self-Supervised MonocularDepth Estimation for Indoor Scenes(GasMono:室内场景的几何辅助自监督单目深度估计)”为题,发表了2篇关于智能无人系统感知领域的最新成果。
针对室内场景自监督单目深度估计中帧间大旋转和低纹理所带来的挑战,研究团队在论文“GasMono:室内场景的几何辅助自监督单目深度估计”中创新地提出了通过多视角几何从单眼序列中获取粗相机姿态,并将视觉变换的全局推理与一种感知过拟合的迭代自蒸馏机制结合起来,提供来自网络本身的更准确的深度引导。此外,受训练数据集中不同场景的尺度模糊性的限制,引入的几何粗糙姿态无法保障性能的提升。为了解决这个问题,研究团队提议在训练过程中通过旋转和平移/尺度优化来改进这些姿态。这项研究成果为室内自监督单目深度估计设定了新的水平,在NYUv2, ScanNet, 7scenes和KITTI数据集上有出色的泛化能力。
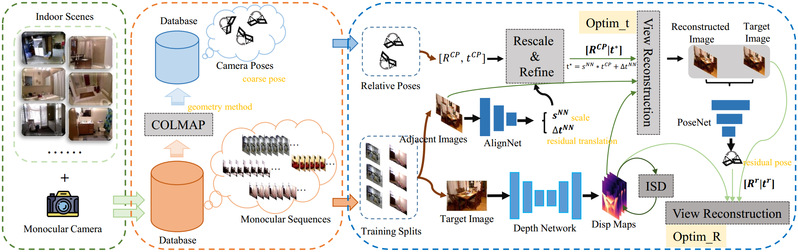
图片说明:几何辅助自监督单目深度估计GasMono框架图
针对夜间图像质量差无法捕捉结构细节和边界信息导致语义分割性能差的问题,研究团队在“CMDA:跨模态域自适应夜晚语义分割”中创新地引入事件相机这一新型的视觉传感器,其具有高动态范围的特点,能对传统相机的不足进行补偿,提升夜间语义分割的性能。在此基础上,研究团队提出了一种新的无监督跨模态域适应(CMDA)框架,利用多模态图像和事件信息在仅使用白天有标签图像的情况下进行夜间语义分割。在CMDA中,分别设计了图像运动提取器来提取运动信息和图像内容提取器来提取内容信息,以弥合不同模态(图像+事件)和领域(白天+夜晚)之间的差距。为了评估算法的有效性,研究团队还提出了第一个图像-事件夜间语义分割数据集,大量实验证明了这项研究成果能够有效提升了夜间语义分割的性能。
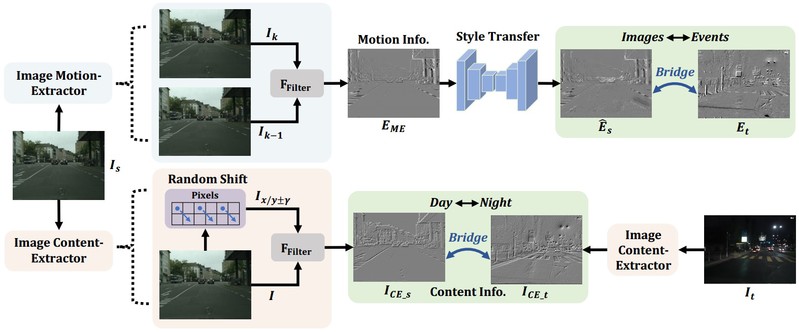
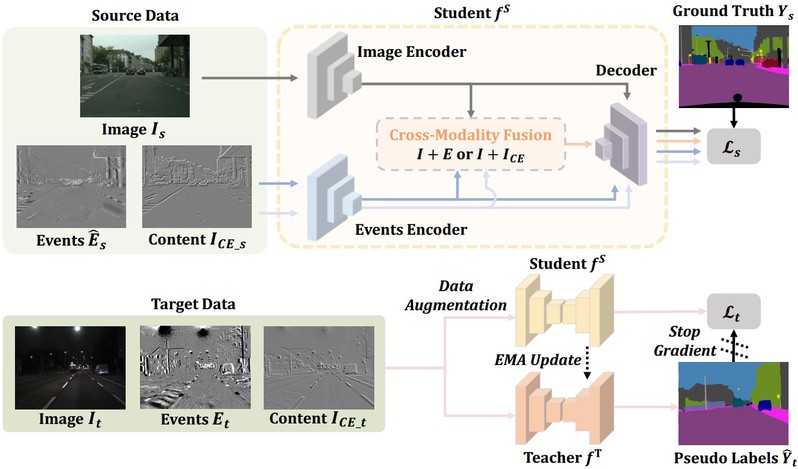
图片说明:跨模态域自适应夜间语义分割CMDA框架图
上述发表于国际计算机视觉顶级会议ICCV2023的成果作者包括博士生赵超强、夏睿豪和国家高层次人才计划入选者唐漾教授等。此外,在前期围绕群体控制,发表了Automatica、 IEEE TAC、SICON论文30余篇,并在智能感知与博弈方面陆续在NeurIPS、CVPR、IEEE汇刊等发表了多篇高水平论文。围绕智能无人系统感知与博弈决策、工业智能等主题,在IEEE TNNLS, IEEE TCYB, IEEE TCASI, IEEE TETCI, IEEE TCDS组织了系列专刊。
相关成果得到了国家自然科学基金基础科学中心项目、国家重点研发计划项目、国家自然科学基金重点项目、国家高层次人才计划和上海市前沿科学研究基地等项目和基地支持,展现了华东理工大学信息科学与工程学院在人工智能前沿领域的最新成果,提升了我校在相关领域的影响力。




