在机器人领域,视觉感知技术的进步犹如赋予了机器一双洞察四方的慧眼。这些技术不仅让机器得以窥见周遭的世界、识别环境中的物体与空间结构,还显著提升了系统的安全性与可靠性,使得机器人能够在复杂且瞬息万变的场景中做出更加精准的决策与行动。目前,感知技术的优化与创新已成为加速智能系统未来发展的研究热点之一。
近日,在中国计算机学会推荐的A类国际学术会议——国际人工智能联合会议(International Joint Conference onArtificial Intelligence 2024,简称IJCAI 2024)和ACM国际多媒体会议(ACM International Conference onMultimedia,简称ACM MM 2024)上,信息学院唐漾教授等分别以“Self-Supervised Monocular DepthEstimation in the Dark: Towards Data Distribution Compensation(自监督夜间单目深度估计:迈向数据分布补偿)”和“Cross-Class Domain AdaptiveSemantic Segmentation with Visual Language Models(基于视觉语言大模型的跨类别域自适应语义分割)”为题,发表/录用两篇关于智能系统视觉感知的前沿研究论文。
针对室外夜间自监督单目深度估计中深度不相关纹理所带来的挑战,研究团队在“基于图像分布补偿的夜间自监督单目深度估计”中创新提出使用图像分布补偿方法对白天图像分布进行昼夜差异补偿,能够引导网络有效克服夜间场景中深度不相关纹理带来的负面影响。此外,考虑到使用风格迁移方法进行补偿具有强目标域指向和关键性深度不相关纹理生成效果差的缺陷,研究团队提出使用物理启发式的方法,对光度分布和噪声分布进行补偿。这项研究成果为室外夜间自监督单目深度估计设定了新的水平,在nuScenes,RobotCar和darkZurich数据集上有出色的泛化能力。
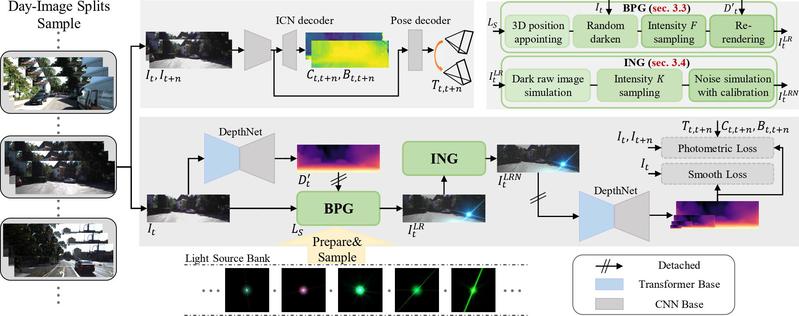
图片说明:自监督夜间单目深度估计数据分布补偿训练框架图

图片说明:自监督夜间单目深度估计框架在nuScenes-Night上的结果图
针对现有的域自适应算法假设源域与目标域具有相同的类别集合,难以对目标域中的新类进行有效分割的问题,在论文“基于视觉语言模型的跨类别域自适应语义分割”中创新性地提出了一种利用视觉语言模型(VisualLanguage Models,VLMs)进行标签对齐的方法,为模型对新类的学习提供更加准确和充分的引导。该方法通过VLMs重新标记新类别的伪标签,解决了目标域中包含未标注或在源域中未见的共享类和新类别的问题。由于VLMs通常仅提供图像级预测,研究团队设计了一种两阶段方法,以实现细粒度的语义分割,并基于伪标签的不确定性设定阈值,以排除噪声预测。此外,为进一步增强对新类别的监督,研究团队还提出了具有自适应更新机制的记忆库,以有效管理准确的VLM预测,并通过重新采样来提高新类别的采样概率。通过全面的实验,研究团队展示了所提方法在各种跨类别域自适应语义分割场景下的有效性和通用性,为该领域的研究提供了新的解决方案。
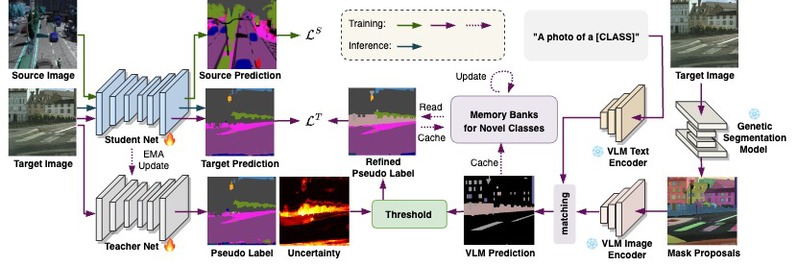
图片说明:基于视觉语言模型的跨类别域自适应语义分割框架图
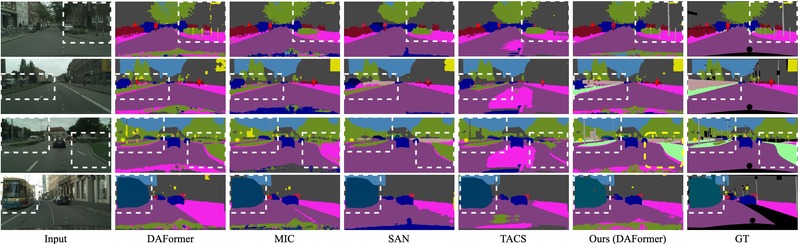
图片说明:基于视觉语言模型的跨类别域自适应语义分割结果图
上述成果作者包括博士生任温琦、硕士生杨昊林、IEEE Fellow/国家高层次人才计划入选者/国家高层次青年人才计划入选者唐漾教授、意大利特伦托大学NicuSebe教授(ECCV 2024程序主席),以及美国联影智能公司的郑梦和吴子彦等。唐漾教授长期围绕智能无人系统、工业智能、生物医药等开展了丰富研究,特别在面向机器视觉和博弈决策的小样本学习和迁移学习方面取得了丰硕成果(ICCV2023, 21572; ICCV 2023, 16209; CVPR 2023, 21560; NeurIPS 2022, 32438; IEEETNNLS 2023, 9604; Nature Communications, 2024, pp. 6288等)。相关成果得到了国家自然科学基金委重点项目、科技部重点研发计划项目、111计划引智项目等多项课题的资助。