近年来,得益于人工智能技术的快速发展,自然语言的理解得到了广泛关注。然而,现有自然语言处理技术仍难以同时保证高准确率和高召回率的复合名词解释,限制了实际应用场景特别是电商领域对复合名词的理解能力。
近期,信息科学与工程学院计算机系团队以第一单位在国际人工智能顶级期刊IEEE Transactions on Knowledgeand Data Engineering(中国计算机学会CCF推荐A类期刊)上,发表了一篇以“Noun Compound Interpretation With Relation Classification and Paraphrasing”为题的关于复合名词解释的最新成果。
在复合名词解释的研究中,现有工作往往采用关系分类或基于释义的方法,前者准确率高而召回率低,后者召回率高而准确率低。针对这一问题,该研究团队提出了一种先关系分类再释义生成的两阶段方法,以此确保复合名词解释的高准确率和高召回率。在第一阶段,作者提出了一种基于复合名词短语、复合名词上下文、复合名词关系图的多视角表示学习方法对复合名词进行关系分类。当复合名词在第一阶段被预测的关系是非语义关系NA或者分类置信度分数低于阈值时,第二阶段(即释义生成)则被触发。在这一阶段,作者提出了一种基于对比学习的槽填充方法来解释复合名词。相比于以往复合名词解释算法,该方法在公开通用领域数据集和领域数据集均取得了最佳效果。
该论文第一作者是信息科学与工程学院计算机系教师刘井平和合作单位复旦大学硕士生刘俊涛,刘井平和复旦大学肖仰华教授是本文的通讯作者。该研究工作已应用于美团APP中的商户打标,搜索系统的点击转化率提高了0.91%。
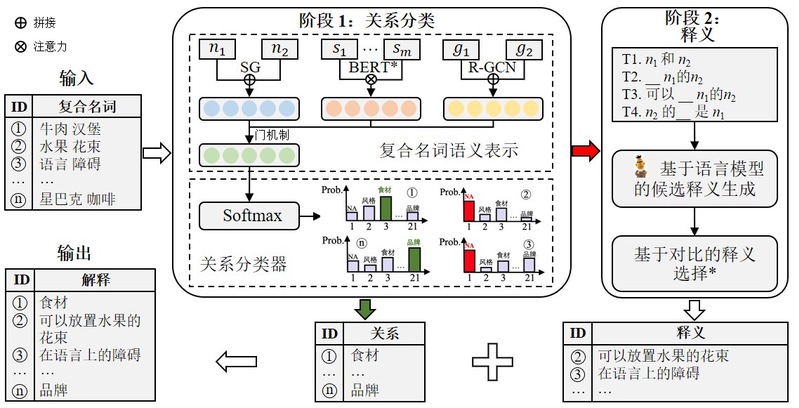
图片说明:复合名词解释框架图