
近年来,得益于人工智能、自动控制和计算机技术的发展,多智能体系统得到了更加广泛的关注。然而,有别于以往关注协同行为的多智能体系统,基于分布式人工智能和博弈理论的多智能体系统在游戏、自动驾驶、智慧城市等领域具有更广泛的应用前景。例如,借助于自博弈的技术,AlphaGo打败了国际围棋冠军,给人工智能领域带来巨大轰动。然而,真正的人工智能远比AlphaGo强大,但还存在许多亟待解决的挑战。
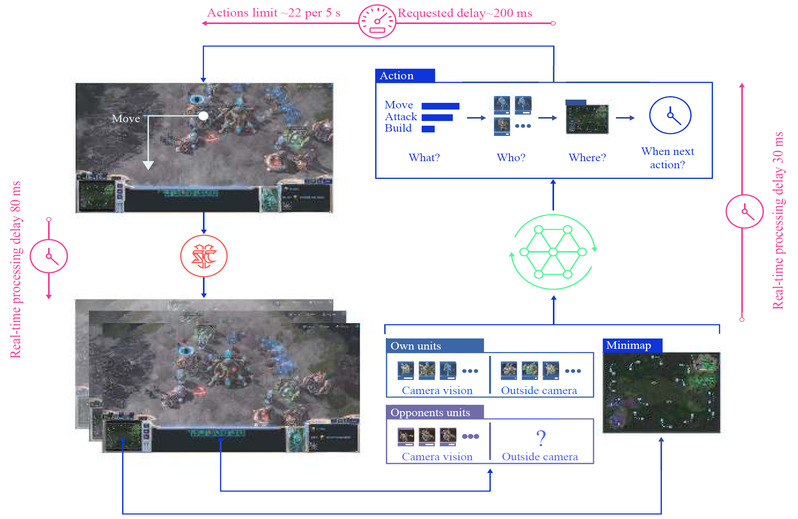
图片说明:多智能体强化学习用于星际争霸游戏AI(Nature, vol. 575, no. 7782,pp.350–354)
近期,信息科学与工程学院在国际人工智能顶级会议NeurIPS 2022(中国计算机学会推荐国际学术会议A类,CCF-A类)上,以“Rethinking Individual Global Max in Cooperative Multi-AgentReinforcement Learning”为题发表了一篇关于多智能体强化学习的最新成果。arxiv上预印本的链接为https://arxiv.org/abs/2209.09640。
在多智能体合作强化学习的研究中,联合的动作空间会随着智能体数量增加而呈指数增长。针对这一问题,联合动作价值分解是一种当前流行的解决思路,此类方法统称为值分解方法(IEEE/CAA Journal of Automatica Sinica, 2022, 9(5): 763-783;SCIENTIA SINICA Technologica, 2022, ISSN1674-7259; Patterns, 2020, 1(4): 100050)。研究团队发现,在具体实现过程中,值分解方法存在一个不被重视但是影响巨大的问题——观测受限导致的学习能力不足。针对此问题,现有方法聚焦于将全局信息嵌入到中间层的网络中,对缺失信息进行弥补,然而此类方法并未关注到因为缺失信息而导致的误差累积问题。
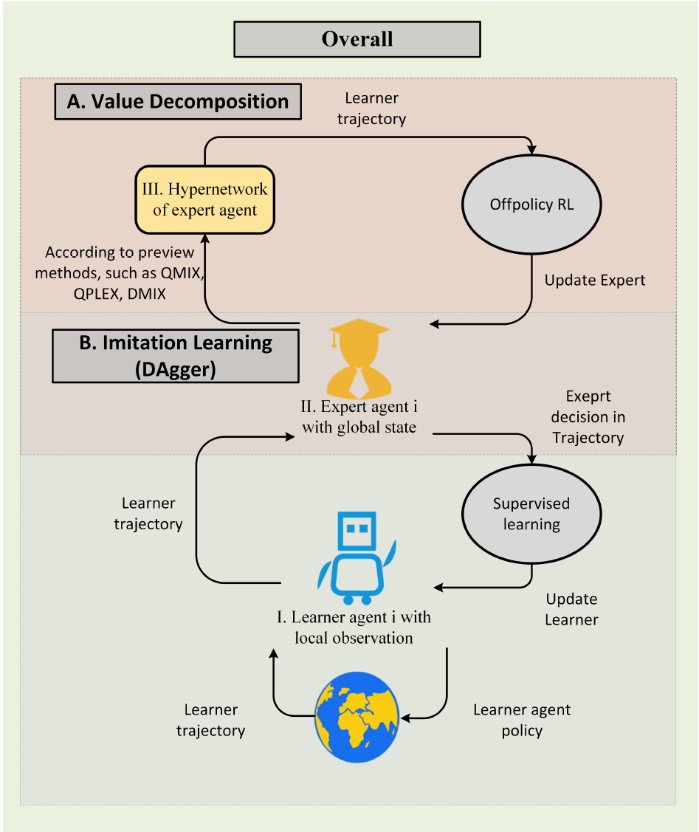
图片说明:改进的训练结构
为了缓解累积误差带来的影响,研究团队提出了融合模仿学习的新型训练结构。与当前先进算法相对比,性能得到了显著的提升。具体而言,研究团队将训练过程分为值分解阶段和模仿学习阶段。在值分解阶段,算法根据历史策略轨迹,利用全局信息计算出改进的专家策略;在模仿学习阶段,算法根据专家策略,蒸馏得到在信息受限情况下学习者的策略。通过所提出的训练结构,将观测受限导致的误差分离到模仿学习阶段,从而避免在值分解训练过程中的误差累积。
该论文第一作者是信息学院计算机科学与技术专业博士生洪艺天,欧洲科学院院士、IEEE Fellow金耀初教授和自动化系唐漾教授是本文的通信作者。研究工作同时得到了中国工程院院士钱锋教授的悉心指导。论文成果得到了国家重点研发计划项目、国家自然科学基金重点项目、国家高层次人才计划、上海市优秀学术带头人等项目资助,以及教育部重点实验室、教育部国际合作联合实验室、上海市工业智能与智能系统前沿科学研究基地的支持。前期相关成果获得了2019年度上海市自然科学奖一等奖。





